Speech Synthesis
Text-To-Speech
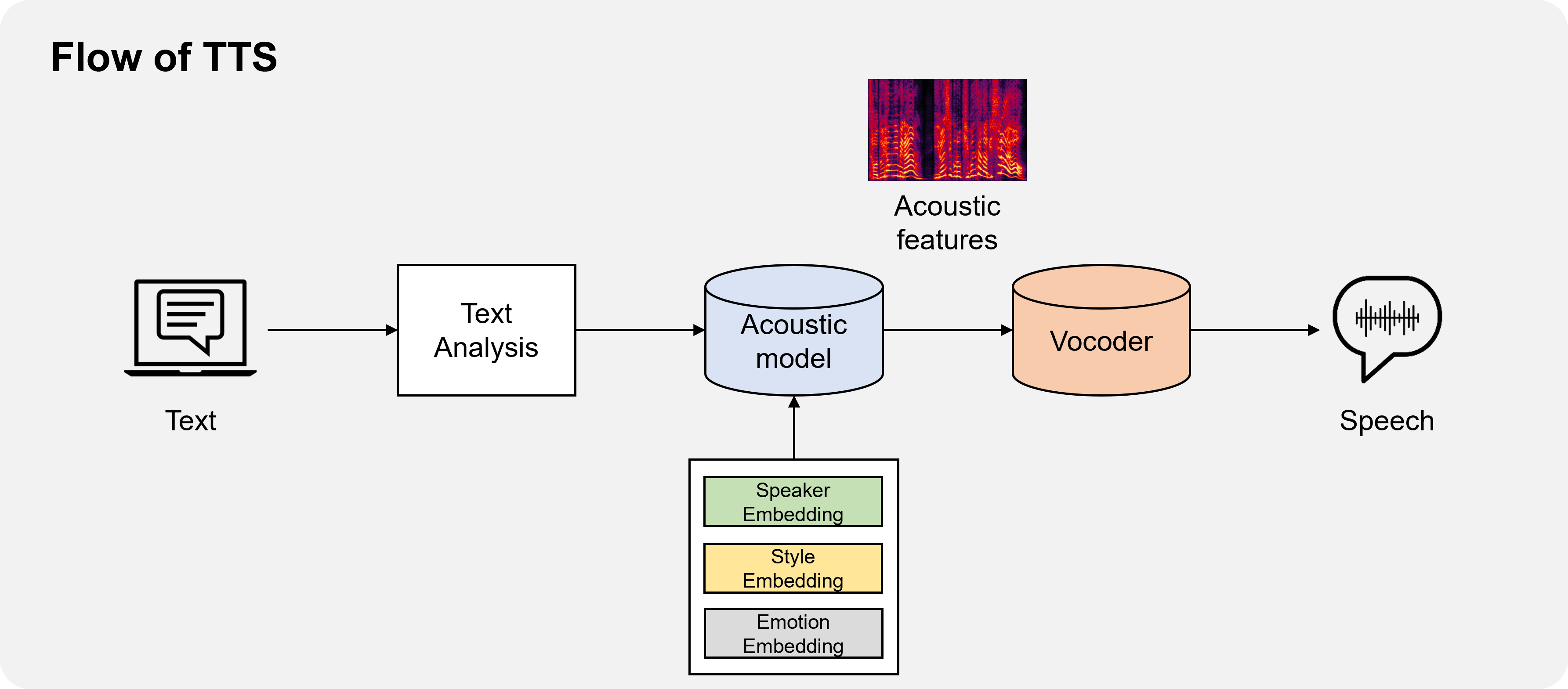
- Text-to-Speech (TTS) system generates speech waveform from the given text
- The ultimate goal of this system is to synthesize a human-like natural voice
- It can generate various speech signal by controlling the condition such as speaking speed, emotion
- This system can be used in many applications such as announcement, Human Machine Interface (HMI)
Synthesized sample
Speed control (Male)
Original
Fast
Slow
Speed control (Female)
Original
Fast
Slow
Multi-Modal Speech Synthesis
- Brain-to-speech and articulatory-to-speech generate audible speech from human signals (ECoG, EMA)
- Encoding a speech-related representation can bridge the gap between speech and brain or articulatory signals
- It can generate various speech signals by controlling the condition such as speaking speed, emotion
- This system can transform the lives of individuals with speech disorder
